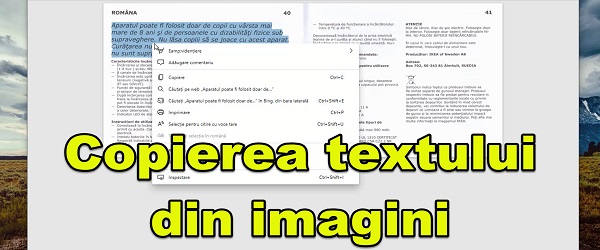
Despre ce este vorba tutorialul video copierea textului din imagini si scanări în limba română ?
Daca ați intenționat vreodată sa copiați textul din documente scanate, sau sa copiați textul din imagini, tutorialul Copierea textului din imagini si scanări în limba română, este pentru voi.
OCR in limba română – Copierea textului din imagini si scanări
La nivel de programe OCR (optical caracter recognition), pentru limba română avem suport destul de subțire, mai ales la programele de PC gratuite.
Din fericire am găsit un soft care este capabil sa recunoască scrisul in limba română si sa-l transforme in text copiabil.
Spun copiabil, pentru ca, evident, formatarea documentului se pierde. Putem doar sa copiem textul, nu sa editam textul din imagine sau din PDF-ul făcut din scanări sau din poze.
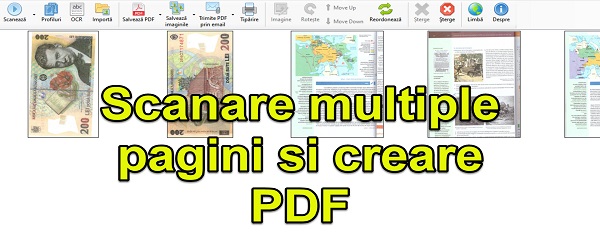
NAPS2 ne sare din nou in ajutor cu OCR in limba română. După tutorialul in care v-am arătat cum se transforma scanările din scaner sau orice alte poze, într-un PDF, acum o sa vedem capabilitatea OCR cu suport pentru limba română a acestui soft gratuit pentru Windows.
Ce înseamnă OCR ?
OCR este abrevierea pentru “optical caracter recognition”. Asta înseamnă ca un soft OCR este capabil ca recunoască caracterele (cifre, litere, semne punctuație) si sa le transforme dintr-o imagine cu informații analog, in caractere digitale, care pot fi copiate si folosite in alt document.
La ce folosește OCR-ul ?
OCR-ul, mai ales daca programul are suport pentru limba română, poate fi folosit pentru:
- extragerea unor citate din cârti tipărite pe hârtie.
- Transformarea unui text din tipărit in digital.
- Recunoașterea si traducerea unor semne in limbi străine (Google Lens)
- Recunoașterea si traducerea ulterioara a instrucțiunile din manuale de utilizare
- Digitalizarea oricărei informații tipărite, pentru distribuire online
- etc, etc, etc
Cum folosim funcția OCR din programul NAPS2 ?
E destul de simplu.
Înainte sa scanam, trebuie sa activam funcția OCR si programul se ocupa de tot. In final o sa generați un PDF, din care veți putea sa copiați textul.
Descărcare NAPS2 – program gratuit creare PDF din imagini sau scanari cu suport OCR in limba română
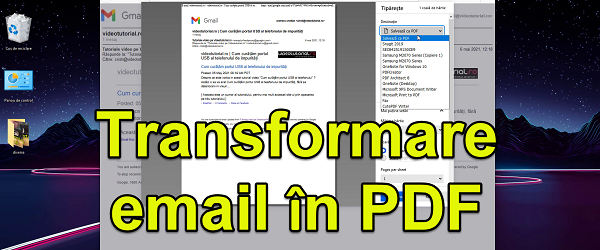
Alte tutoriale video cu OCR, PDF, scanare, etc:





Nu vreau să fiu rău, dar cum în engleză e la pagina 4 și în română la 40? Nu merge OCR la mine. În cazul PDF-urilor importate, se poate porni OCR?
Scuze, nu știu de ce aveam în cap că face și traducere.
Nu merge programul :((
Folosesc de multi ani ABBYY FineReader, recunoaste perfect limba romana si mi se pare mai performant si mai rapid de utilizat fata de ce ne-ai prezentat!…
Foarte bun!, nu pastreaza formatarea, dar important e textul, multumim